DeepSeek新突破:解读SPCT技术与通用奖励模型DeepSeek-GRM
引言 近期,国内人工智能公司DeepSeek在大型语言模型(LLM)领域再掀波澜,发布了一项名为SPCT(Sparse Pre-training and Context Tuning)的新技术,旨在提升通用奖励模型(General Reward Model, GRM)的性能和AI对齐效率。这项技术不仅展示了DeepSeek在模型优化方面的深厚实力,也可能预示着其下一代模型(如传闻中的R2)...
引言 近期,国内人工智能公司DeepSeek在大型语言模型(LLM)领域再掀波澜,发布了一项名为SPCT(Sparse Pre-training and Context Tuning)的新技术,旨在提升通用奖励模型(General Reward Model, GRM)的性能和AI对齐效率。这项技术不仅展示了DeepSeek在模型优化方面的深厚实力,也可能预示着其下一代模型(如传闻中的R2)...
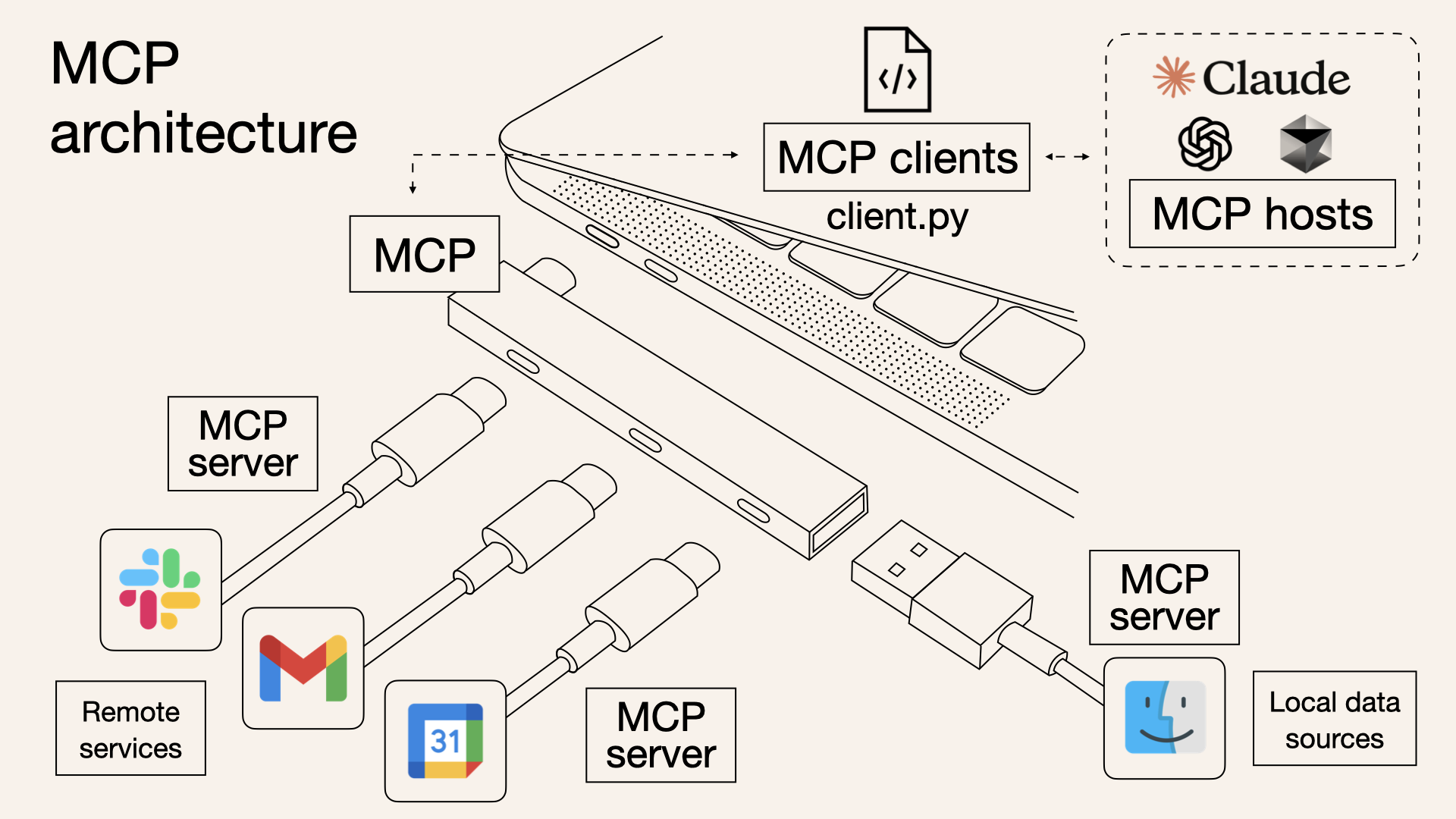
深入解析模型上下文协议(MCP)的工作原理、架构设计与实现方法,包含Java与Python示例代码,帮助开发者快速理解并应用这一AI工具标准化集成方案。

从工程开发者角度深入解析Milvus向量数据库的核心概念、架构设计与实现原理,包含Faiss、HNSW等向量搜索算法详解,助力RAG系统构建。

全面解析大语言模型(LLM)的核心概念、Transformer架构、训练技术与优化方法,帮助开发者深入理解LLM的工作原理与实现细节。